










Machine learning is a data analysis technique that builds a model with the data and uses the model to predict. It learns from the data, identifies patterns and produces reliable predictions that help with decision making. As modern computational techniques advance, machine learning becomes more and more popular. There are two major groups of learning algorithms, supervised and unsupervised learning. Many regression and classification models we know of are supervised learning, such as linear regression, lasso regression, support vector machine, decision tree classification, random forest classification. They are supervised in the sense that the data we use to train the model have a “correct” label. And using this information, we can evaluate the performance of the learned models. On the other hand, when the data we used for training don’t have any label information, it is unsupervised. For example, clustering algorithms such as k-means assign data into groups. In this process, it doesn’t require the training data to have the correct labels as references.
Simlytiks-ML
Simlytiks-ML is a machine learning feature on d3VIEW Simlytiks. It has incorporated the most commonly used machine learning techniques and provides an option for users to perform these machine learning methods without any specific programming knowledge with an user-friendly interface.
HIC dataset
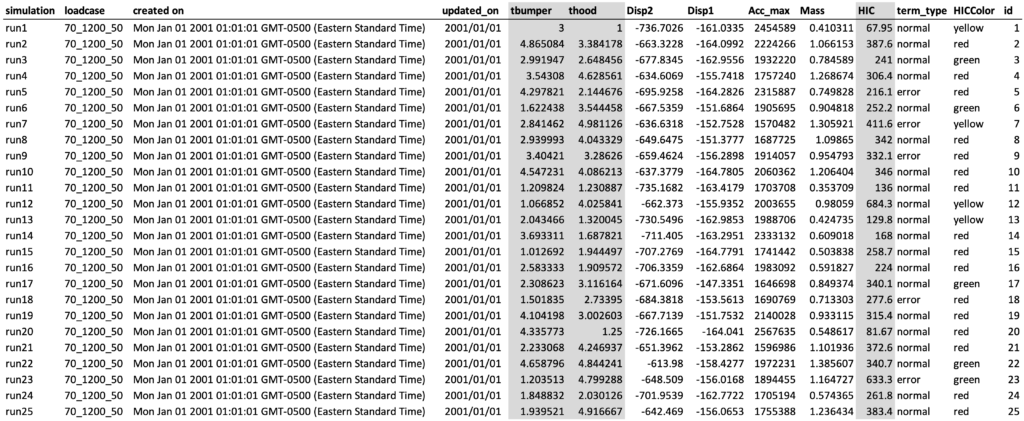
When we click “New Dataset”, we choose the dataset “Simulation DOE Results Small” from the list of sample data. The dataset contains records from a simulation study about HIC values. Here we are interested in predicting HIC values with “thumper” and “thood”. Since “HIC” is a numeric variable, we can use regression methods for the learning. Next to the option to “add visualization”, there is a new green icon “ML” which will provide us a list of machine learning algorithms for us to select.

Linear regression
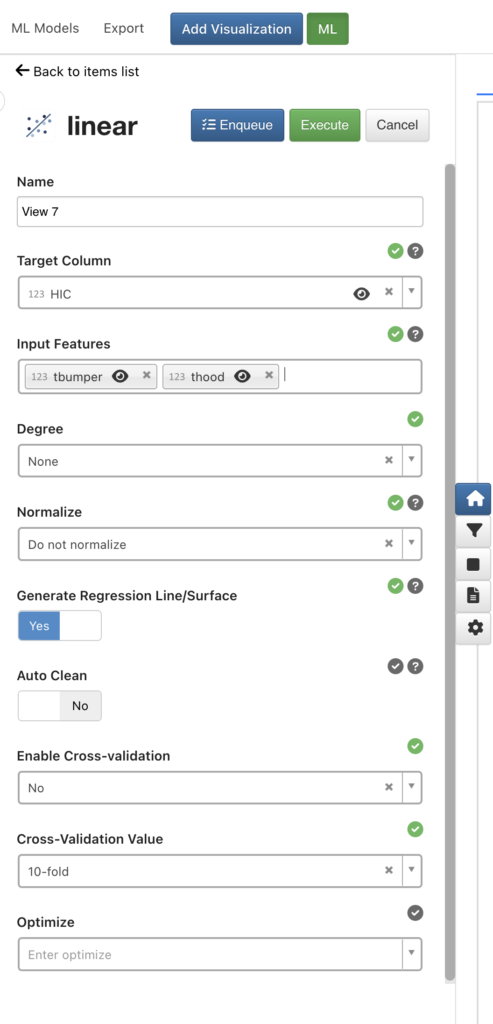
Linear regression is one of the most popular and straightforward machine learning technique. To perform a linear regression, we click “ML” and select “linear regression” in the list. Then we are prompted to decide the configuration of the analysis. For example, the target and input features. In this case, “HIC” is the target since that’s what we want to predict and “tbumper” and “thood” are the features we will be using to predict “HIC” values, thus they are the input features. There are also options for us to choose the degree for our linear regression model, if we want to normalize the data before we learn the model and if we want to “clean” the data when there are missing values in the data. Here we just use the default settings and click “execute” to train our linear regression model.
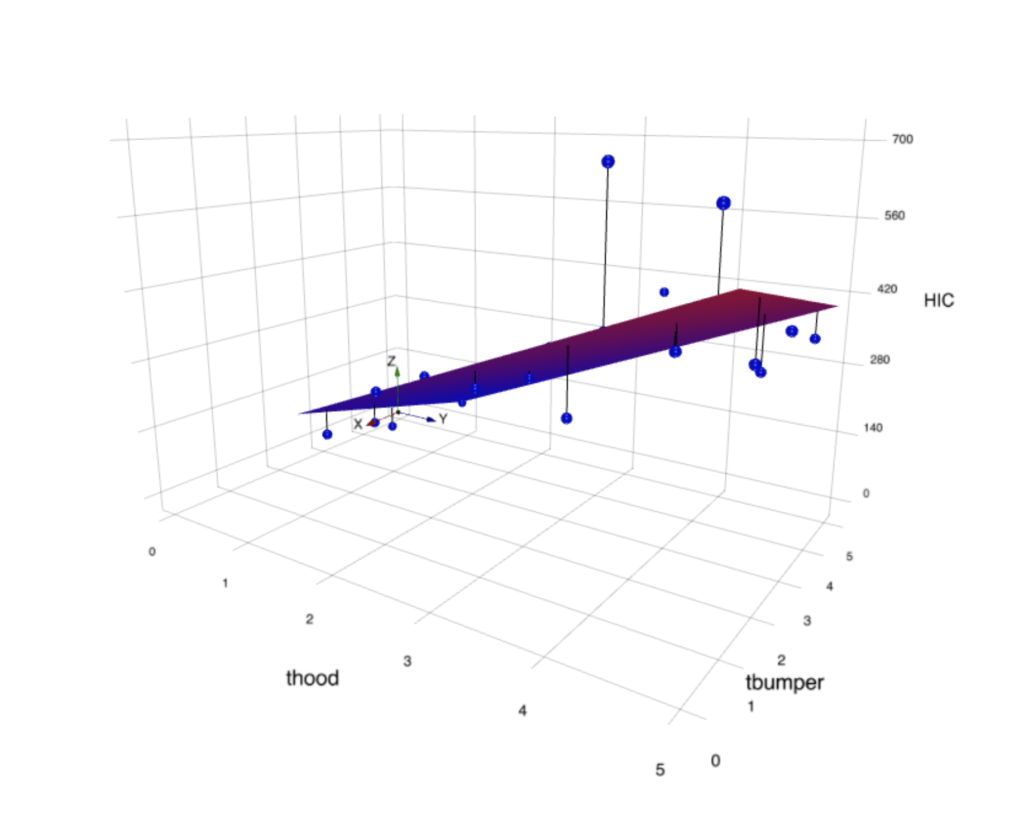
After the linear regression model is trained, we will see a three dimensional scatter plot visualization of our input data, together with a regression surface we have learned from the data.
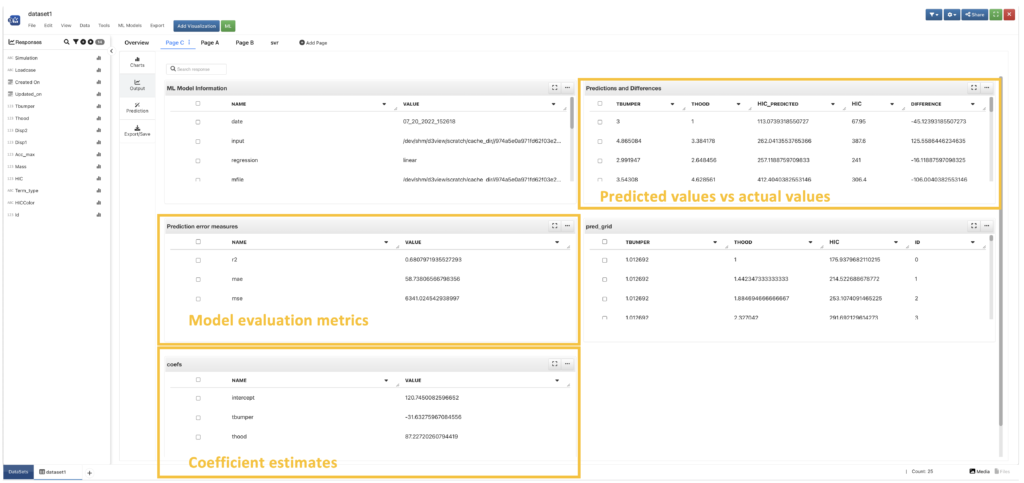
More details on the model we have trained are available in the “output” section. The most important and helpful information is the coefficient estimates which we can use for predicting new data, the predicted values right next to the actual values from the dataset as a comparison, model evaluation metrics such as R2 (R squared), MSE and MAE. This gives us an idea how our model performs and it can be used to compare our model with the others.
Here we show the results derived from R software. Compared to what we get from Simlytiks-ML, we have the same coefficient estimates and the same computed metrics (R2, MSE, MAE).

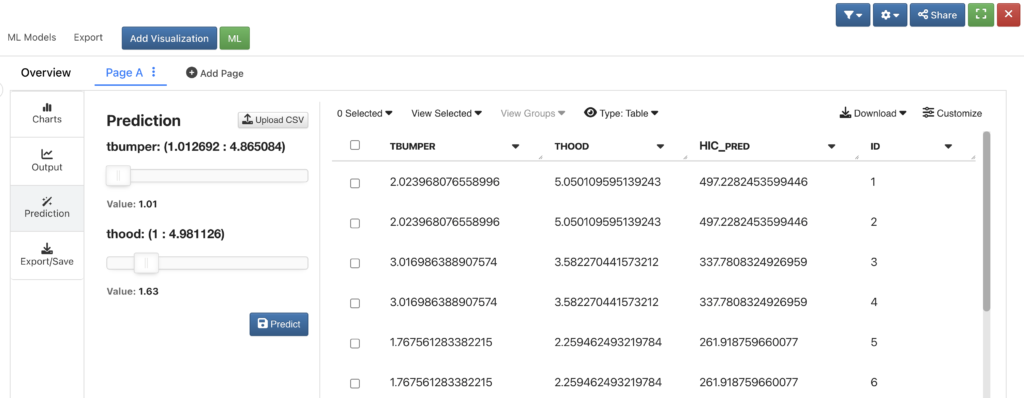
Prediction
It is intuitive that we want to make some predictions after we have trained our model. In Simlytiks-ML, we can go to the “prediction” section, and directly upload a csv file containing new data. The predicted values will show up on the right.
Comparison of different models
Just like how we performed a linear regression analysis, we can easily train some more advanced models with Simlytiks-ML. For example, we can choose “lasso”, “support vector regression” or “random forest regression” in the listed methods provided in the “ML” option. The coefficients of these trained models are summarized in the table below, together with that from the linear regression methods. Together, we can compare between different models and see which one performs better. In this case, our trained random forest regression model outperforms the other models on all metrics. For a more rigorous comparison, we can add the cross-validation procedure to make sure that the random forest model doesn’t perform better than the other models by chance.

Conclusion
As demonstrated above, Simlytiks-ML provides a convenient way for users to conduct all types of machine learning on the data without intensive programming and make predictions by uploading a csv file containing new data. Users only need to focus on the methods from the conceptual level and results are presented in an easy-to-understand manner.
