Machine learning techniques (https://www.d3view.com/introduction-and-application-of-d3view-ml/) are becoming unprecedentedly popular. And it plays an important role in data analysis. It is critical to find the model that demonstrates the best performance. Intuitively, we can build a few different models with the data given and see which model gives the best score, either it being RMSE (root mean squared error), R squared for regression models or accuracy, precision for classification models.
Overfitting
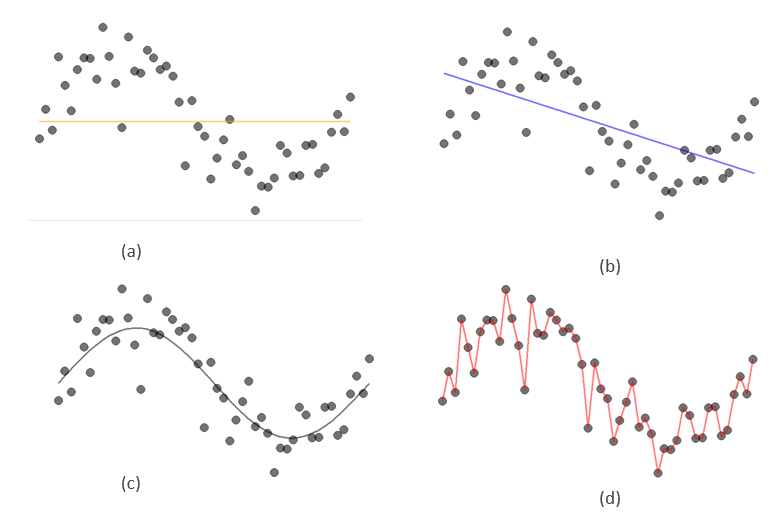
You may have already sensed the problem with this approach. A more complicated model is always going to perform better. An extreme example is we can just connect all data points with lines or equivalently assign y values to each x values as they are in the given data. The error will be zero. However, when this complex model is applied to some new data, it will produce more errors. This is called overfitting. It happens because data contain noises or random errors. For example, when we are measuring a person’s height multiple times, we may have different readings each time due to factors such as the angle of our eyes to the reading, or the light in the environment or simply we want to quickly finish the work and move forward. Though the person’s height remains unchanged, the readings we have are different. These noises generate uncertainty in the target y values. Therefore, a good model should keep this uncertainty to its consideration.
Cross validation
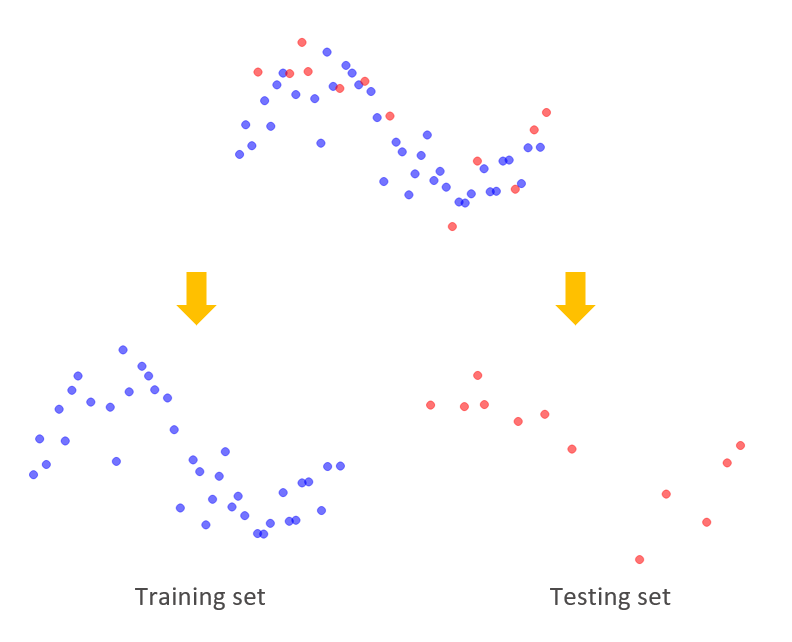
As we observed previously, a well performed model trained using the existing data may perform poorly with new data. This suggests that we need to have two different sets of data to build the model and test the model. The procedure of splitting the data randomly into two different sets to build and test models is called cross validation. And the two sets are called training set and testing set.
Since we split the data randomly, there is a chance that the data from a particular testing set fits the model trained from training set perfectly although the model itself may not be the closest to the true model. Or the opposite can happen, the data from a particular testing set just happen to be outliers and thus gives a very poor score for the trained model. What we can do to avoid such situation, is to repeat the split-train-test cycle a few more times and average the scores. This process will reduce the chance the score is biased to the very poor and very good data from the testing set. This is called k-folds cross validation.
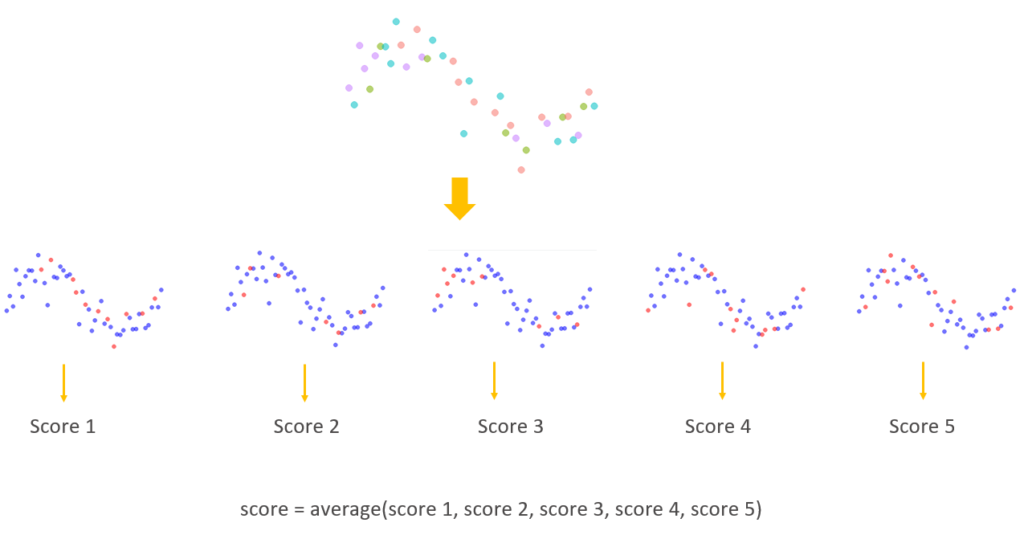
We randomly split the data into k folds. And use each fold as a testing set once and the remaining folds together as the training set to build a model to be tested on the testing set. Each testing set will have a score. By averaging these scores, we get an overall score for the current model which reduces the chance being biased due to the quality of the data from testing sets.
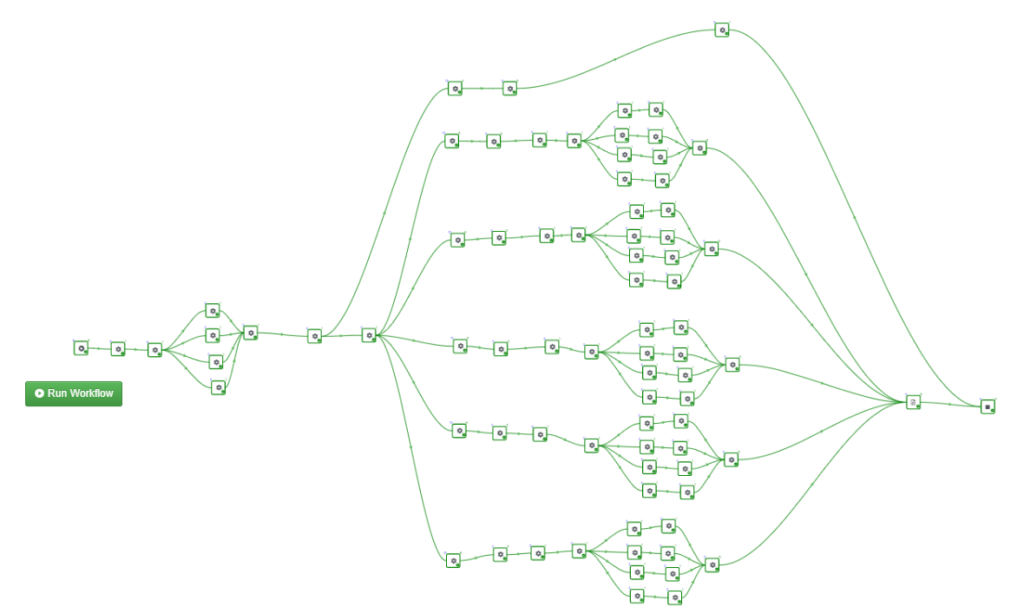
Cross validation on d3VIEW Workflow
There are some simulations curves and we are interested in the relationship between these curves to the values of some parameters inputs for generating these simulations curves.
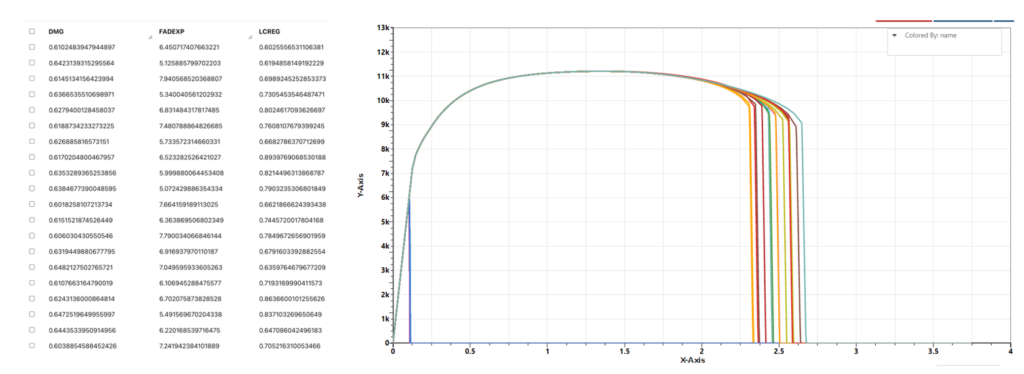
We can consider y value of each point on the curve as a target we want to predict based on the input parameters. So, this becomes a multivariate multi-responses regression problem. Here, we will just use linear models with of different polynomial degrees and see which model has a better performance.
If we use all the data to build model and evaluate their performances, it is not surprising that the most complicated model (with the highest order) has the best performance.
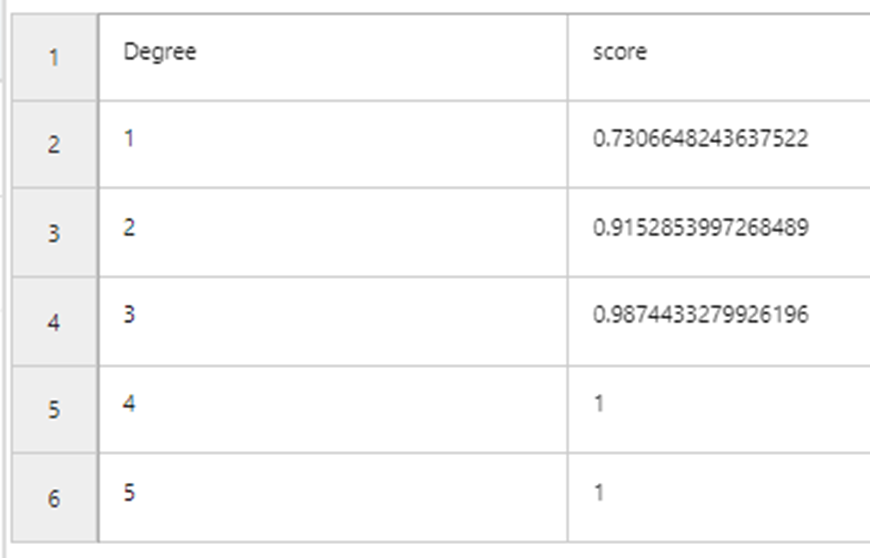
Now we add a 10 folds cross validation to the model building stage.
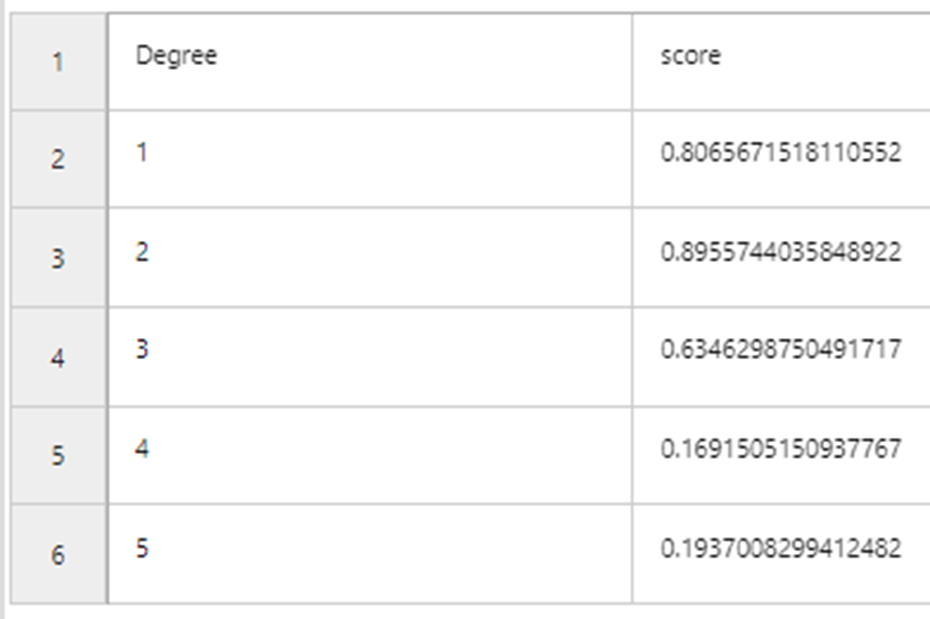
As we can see, overcomplicated models tend to overfit. From this cross validation output, we can conclude that the best model is linear model with degree 2. We can see this from predictions that curves predicted from linear model with degree one has relatively large errors and those from linear model with degree three have fit the curves very well (overfitting!). Predicted curves from the linear model with degree two is in between the two models.
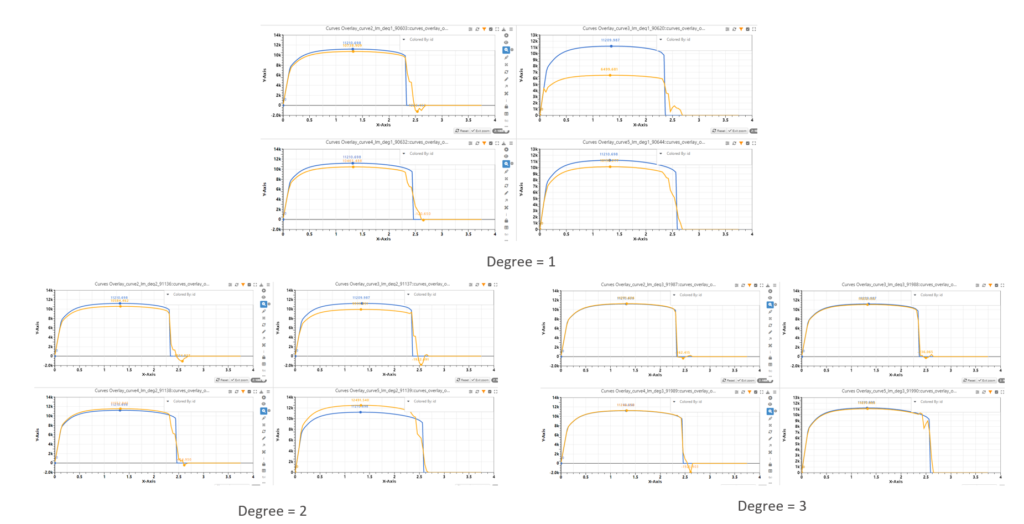
In d3VIEW, we can set up the cross validation in the ML_Learn workers and build a workflow that trains the model and performs cross validations for different models and generate a report that shows the results we are interested to see.